人工智障之 RNN 词嵌入基础
 Niku
Niku本篇记录自己在做李宏毅机器学习 2020 作业 4 中所涉及的 NLP 相关基础知识。
简要总结了对词嵌入模型的理解。
词嵌入 word2vec
在 NLP 有关的项目中数据大多是文本语料,这样的数据无法直接放入模型中进行训练,往往需要将词处理成向量后为如模型训练。处理这样的离散的文字序列常用的一种方法就是 one-hot 编码。 有多少个词就有多少向量,如:
| |
然而这样处理文本数据存在很大缺陷,当语料库非常大时,这样产生的词向量也变得非常长,维度稀疏的数据本身就十分不利于模型训练。
并且 one-hot 编码产生的向量本是独立正交的,因此无法保留各个词之间相关联的信息。
而使用词嵌入(Word2vec)的方法可以很好地解决该问题(最新的 BERT 还不了解放到后面的文章再写)。Word2vec 将词从 one-hot 编码形式降维,并且包含词语词之间的关联信息。Word2vec 有两种模型, Skip-gram 和 CBOW 。 Skip-gram 的思路是输入中心词,输出相关联的多个词, CBOW 是输入多个词输出与这些词关联的中心词。

Skip-gram
这里只谈直观理解,不对算法的实现与优化作说明,感兴趣可以阅读相关论文
- 训练样本:中心词和中心词左右 skip_window 大小的其他词。
- 模型输入:输入中心词的 onehot 编码。
- 模型输出:输出一个概率表示每个词有多大的概率和中心词同时出现。
- 损失函数:因为输入为 onehot 输出为同样维度的概率,因此可以直接计算这两个的交叉熵作为损失。
输入数据通过一个无激活函数的隐藏层(降维),后通过维度与输入一样的 softmax 层输出概率。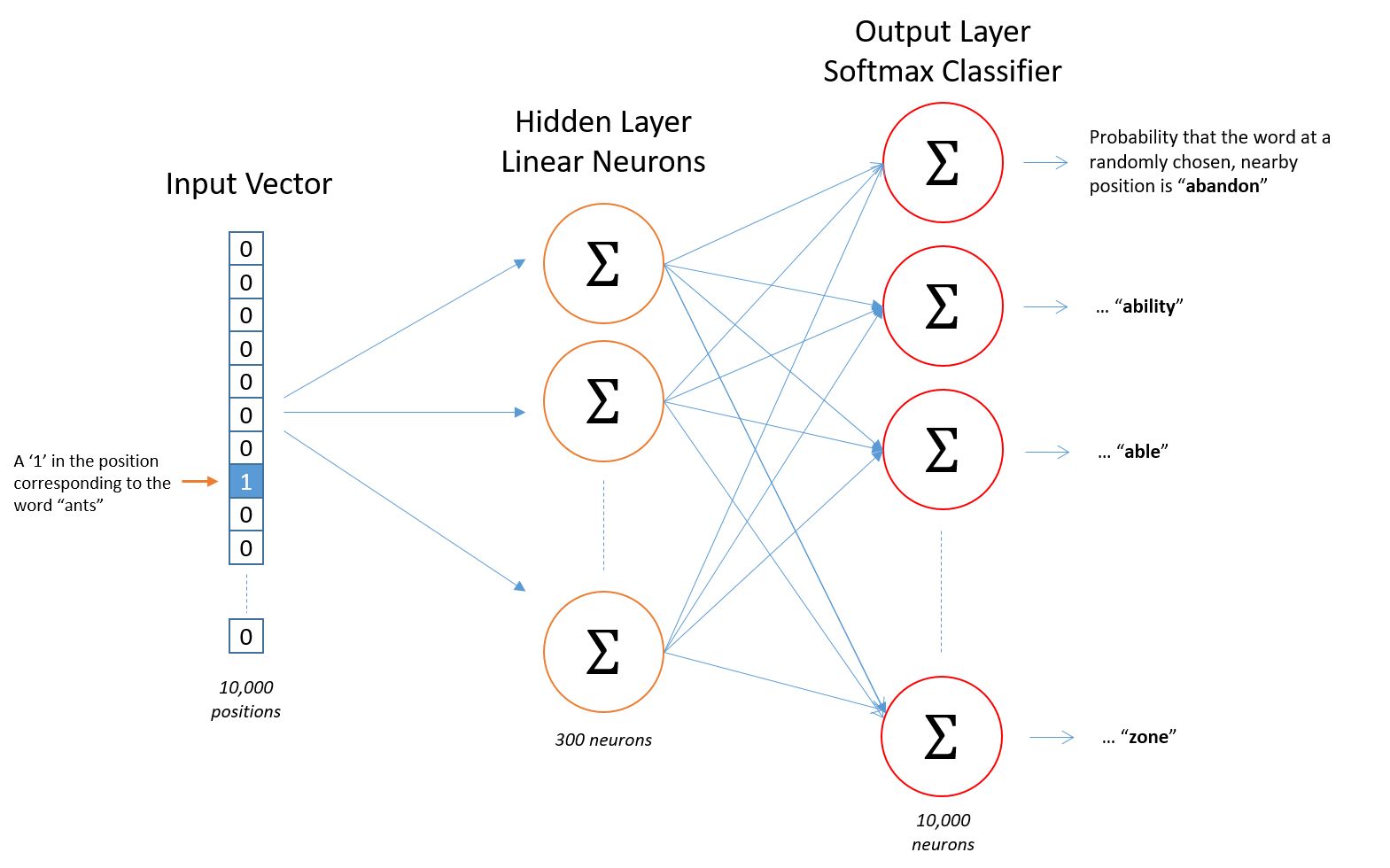
模型结构

看到模型结构会发现,其实 Skip-gram 本质就是一个预测模型,这个模型做的是给出一个中心词,去最大化他周围词的预测概率,在这过程中训练出的低维的隐藏层权重就是我们需要的词向量。
CBOW
CBOW 原理和 Skip-gram 相同,只不过在输入的时候是该词周围的词向量加总作为输入。
- 输入:中心词附近 skip_window 大小的其他词的 one-hot 编码求和。
- 标签:中心词的 one-hot 编码。
- 输出:预测对应中心词的概率。
一个栗子
比如我们有 10000 个词的 one-hot 编码,我们想用词嵌入将 10000 的编码降维到 300。
于是我们使用 Skip-gram 或者 CBOW 模型进行训练。由于降维到 300 于是我们把隐藏层神经元个数设为 300 的全连接结构,即这里有 10000*300 的参数即词向量。
当我们要调用的时候,可以根据次的 one-hot 编码中 1 所在的位置查询这个词对应的 300 维的向量。
当然作业代码实现里直接使用了 gensim 包实现该模块,注意 gensim 4.0 版有些改动,需要略微修改范例代码。